让不懂建站的用户快速建站,让会建站的提高建站效率!


剪辑:alan
代码模子不错我方进化,诈欺自己生成的数据来进行指示调优,成果超过GPT-4o班师蒸馏!
LLM手脚智能的基座,不错繁衍出各式智商。
代码智商即是其中一种:规范补全、细心、优化、修bug、测试等等。
而念念要充分阐述LLM的庞杂后劲,指示调优(Instruction Tuning)是至关遑急的一步。
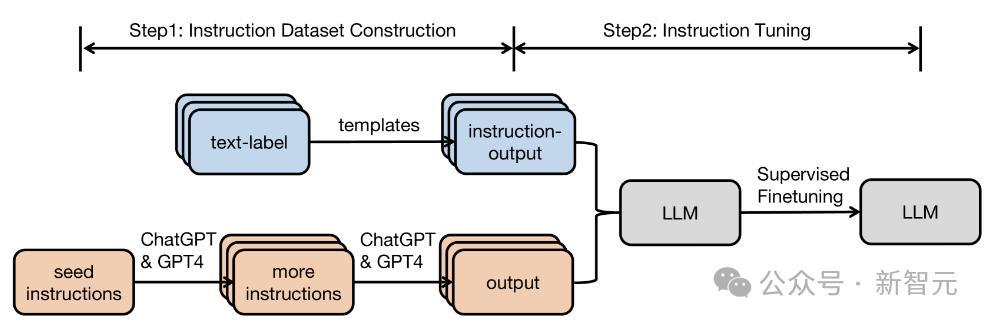
刻下,高质料指示数据主要有两个来源:东说念主工细心和蒸馏。
前者很贵,后者则受到抓法。于是,东说念主们初始别有肺肠。
近日,来自UIUC、伯克利等机构的琢磨东说念主员提议了SelfCodeAlign。
这篇责任初度讲明了,不错通过自对皆(Self-Alignment)来赢得刚烈的代码模子,不需要东说念主工细心约略蒸馏,而况成果更好!

论文地址:https://arxiv.org/pdf/2410.24198
SelfCodeAlign在通盘数据生成过程中,使用换取的基础模子进行推理,分为三步:
率先,从高质料的种子片断中索求不同的编码想法,以生成新任务。
然后,对每个任务的多个反映进行采样,将每个反映与测试用例配对,并在沙盒环境中对其进行考证。
临了,遴荐考证通过的示例来进行指示调优。

SelfCodeAlign是第一个透澈透明的pipeline,使用纯自生成的指示数据对基础代码模子进行自对皆。
实验标明,使用SelfCodeAlign对CodeQwen1.5-7B进行指示微调,在HumanEval+上竣事了67.1 pass@1,逾越了参数目大10倍的CodeLlama-70B-Instruct。
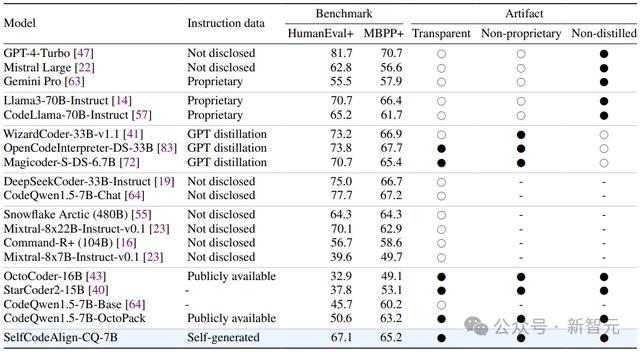
在一起的三项基准测试(代码生成、数据科学编程、代码剪辑)中,SelfCodeAlign都慑服了之前最先进的指示微调方法OctoPack。
此外,在HumanEval+上,SelfCodeAlign的性能超过了基于GPT-3.5-Turbo的蒸馏方法(包括 OSS-Instruct(61.6)和Evol-Instruct(59.1)),以至击败了GPT-4o的班师输出蒸馏(65.9)!

这意味着,从模子我方的数据别离对皆中学习,可能胜于使用刚烈的teacher模子。
SelfCodeAlign适用于各式限制(从3B到33B)的LLM,比如StarCoder2-Struct就所以此为基础创建的(base model为StarCoder2-15B)。

自对皆代码生成
下图以StarCoder2-15B的指示调优过程为例,展示了SelfCodeAlign的历程:
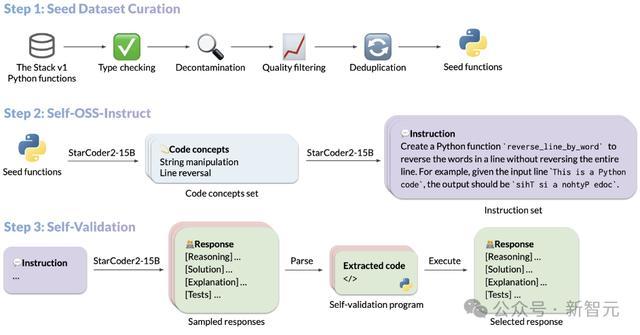
种子遴荐
SelfCodeAlign率先从The Stack V1中积聚一组种子代码片断。
此门径中,确保种子片断万般化且高质料至关遑急,它们将用作生成证明和反映的开始。
为了积聚种子片断,琢磨东说念主员从The Stack V1中索求统管辖有文档字符串的Python函数,然后应用一系列过滤章程来确保种子片断的质料。
通过运行Pyright类型检查器、删除基准项、过滤掉文档质料差的函数,以及删除果然近似的函数,总计从5M个函数中过滤出250k个Python函数。
想法生成
积聚种子函数后,初始实践Self-OSS-Instruct,对OSS-Instruct的自对皆进行修改,以生成不同的指示。
具体来说,这里领受高下文体习(In-context learning)让基础模子从给定的种子代码片断中自行生成指示。
### System : I - > R You are an extremely intelligent AI coding assistant . Please provide an accurate and reliable response to each user instruction . After delivering your response , verify its consistency and correctness by writing a series of executable tests . ### System : C - > I Create a series of independent coding tasks that are original , distinct , diverse , and high - quality , fostering logical thinking . Each task must adhere to specified properties : - category : the type of task ( e . g . , function implementation , class implementation , or program implementation ) - language : the programming language to be used - difficulty : the complexity level of the task ( e . g . , easy , medium , or hard ) - concepts : fundamental principles and techniques the task is designed to incorporate ,股票高杠杆配资 which developers must understand to effectively solve the task Design the tasks so that the relevant concepts emerge naturally as the most appropriate solutions , without explicitly mentioning that a particular concept should be used .
作家使用了21个用心绸缪的示例来教模子若何责任:

指示生成过程分为以下两个门径:
想法索求:关于每个种子函数,领导基本模子生成函数中存在的代码想法列表。代码想法是指编程中使用的基本原则和时刻,举例模式匹配和数据类型调遣。
指示生成:领导基本模子字据已识别的代码想法和两个附加属性(难度和类别)自生成编码任务,当场抽样以丰富生成指示的万般性。
实践筛选
字据Self-OSS-Struct生成的指示,下一步是将每条指示与高质料teacher模子(比如GPT-4)相匹配。
不外,好多刚烈的买卖模子不允许用蒸馏来作念这种事,而况,teacher模子也不一定就愈加锐利,毕竟敦厚也会犯失误,这时就会起到负作用。
作家建议,明确开采模子在产生与当然话语交错的反映后,生成用于自我考证的测试来自对皆基本模子。
具体来说,关于每个指示,基本模子对模式的多个输出(反映、测试)进行采样,然后过滤掉那些在沙箱环境中测试失败的反映。然后,为每个指示当场遴荐一个考证通过的反映,应用于最终的指示微调数据集。
实验评估
本文全面评估了SelfCodeAlign在各式编码任务中的推崇,包括:
函数生成:给定当然话语刻画,条款LLM生成一个自包含函数,并测试函数的正确性和遵循。
类生成:给定一个包含类级和方法级信息的代码框架,条款LLM生成类偏抓方法。
数据科学编程:给定数据科学任务的刻画和部分代码片断,条款LLM完成代码片断以通过相应的测试。
文献级代码剪辑:提供文献本体后,条款模子按照当然话语指示剪辑规范。
函数级代码生成
平允起见,比较对象为类似限制的最先进的开源模子,基准测试遴荐LiveCodeBench。
LiveCodeBench是无混浊评估的基准,包含2023年5月至2024年2月时辰的400项最新Python算法挑战。这些任务来自Codeforce和LeetCode等网站,每个网站平均有20多个测试用例。
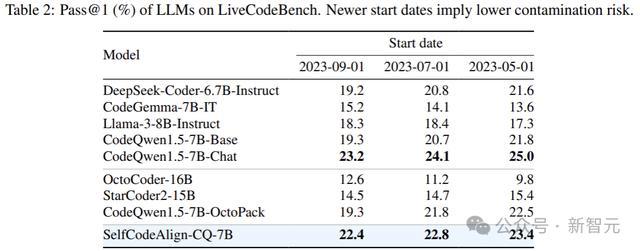
上表陈说了在3个特定初始日历之后创建的问题的测试扫尾(pass@1)。SelfCodeAlign-CQ-7B的性能长久优于大多半基线模子。
此外,将初始日历上前移动对SelfCodeAlign-CQ-7B的影响很小,这标明模子不太可能受到混浊。
类级代码生成
这里使用ClassEval评估类级代码生成的智商,ClassEval是100个类级Python代码生成任务的聚会,涵盖100个类和410个方法,平均每个类33个测试,每个方法有8个测试。
作家将最大高下文大小缔造为2048个token,测试了三种生成政策中每个模子的最好类级pass@1(以及相应的方法级pass@1):
1. 合座生成:在给定类框架的情况下生成通盘类;
2. 增量生成:将早期生成的方法放在领导符中来迭代生成类方法;
3. 组合生成:零丁生成每个类方法,不稽察其他方法。
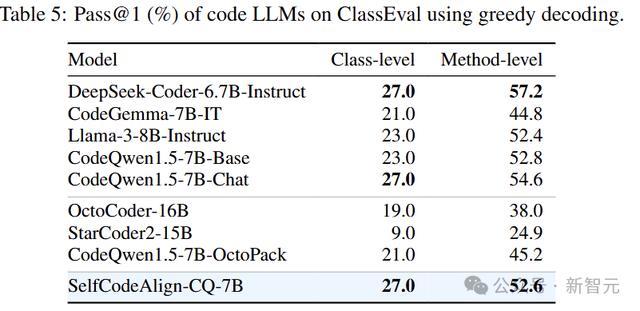
上表中的类级pass@1需要同期生成正确的类和方法,而方法级pass@1仅检查生成的方法是否能通过方法级测试。
上表的扫尾表示,就类级性能而言,SelfCodeAlign-CQ-7B是推崇最好的,不管是比较于开源指示微调模子,依然使用未知或尽头指示微调数据的模子。
数据科学
DS-1000包含7个流行的Python数据科学库中1000个执行数据科学挑战。在这个基准测试中,模子必须完成部分代码片断材干处置问题。
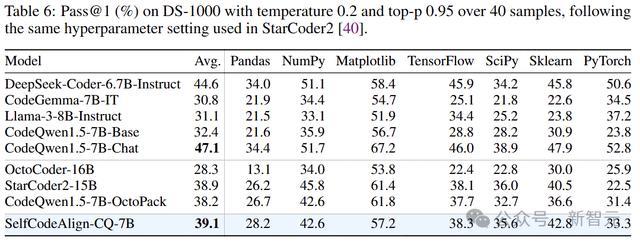
上表表示,尽管SelfCodeAlign-CQ-7B只使用了有限的数据科学代码进行素质,但在与一众模子的比较中仍然推崇出色。
代码剪辑
代码剪辑任务遴选CanItEdit手脚基准测试,该基准测试由三种类型的210个代码剪辑任务(每种类型70个任务)构成:转换(莳植失误)、自相宜(添加新功能)和完善(立异现存功能)。
关于每个任务,模子需要以原始代码片断和刻画所需代码改造的当然话语指示手脚输入,生成闲适指示的代码片断。驯顺原始基准测试中的缔造,在0.2的温度下为每个任务进行20次测试。
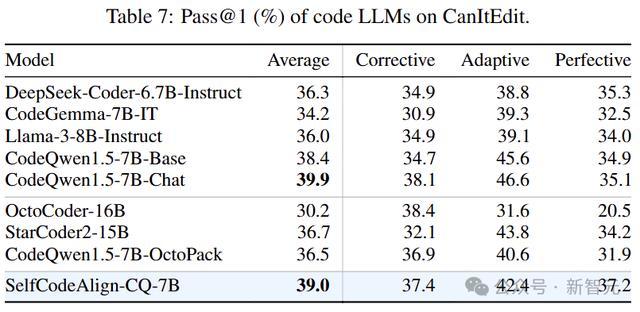
上表陈说了每种类型的pass@1以及统统任务的平均得益。尽管莫得挑升针对代码剪辑进行调优,但SelfCodeAlign-CQ-7B在CanItEdit上推崇出刚烈的性能,竣事了39.0%的pass@1天宇优配,优于除CodeQwen1.5-Chat除外的统统模子。